 Technologia Informacyjna
Technologia Informacyjna

Systemy mikroprocesorowe
Model programowy procesora
 |
Model programowy procesora - zestaw zasobów logicznych komputera dostępnych dla programisty piszącego program użytkowy w języku asemblerowym lub dla kompilatora translującego program użytkowy napisany w języku wysokiego poziomu do postaci asemblerowej. |
Model programowy nie ma bezpośredniego związku z budową wewnętrzną procesora i komputera.
Składniki modelu programowego procesora:
- zestaw rejestrów (liczba i funkcjonalność rejestrów procesora)
- zestaw trybów adresowania (sposoby specyfikacji argumentów operacji)
- model operacji warunkowych (sposób realizacji konstrukcji warunkowych)
- lista instrukcji (zestaw operacji, jakie może wykonać procesor)
Rejestry
|
Rejestr - to komórki pamięci o niewielkich rozmiarach (najczęściej 4/8/16/32/64/128 bitów) umieszczone wewnątrz procesora i służące do przechowywania tymczasowych wyników obliczeń, adresów lokacji w pamięci operacyjnej itp. |
Rejestry:
- akumulator
- rejestr adresowy
» bazowy
» indeksowy
» wskaźnik stosu, ramki - licznik pętli
Architektury rejestrów:
- brak (pamięć - pamięć)
- minimalny
- mały zestaw rejestrów specjalizowanych
- mały zestaw rejestrów uniwersalnych
- duży zestaw rejestrów uniwersalnych
- zestaw rejestrów jako bufor ramki stosów
- stosowy zestaw rejestrów
Tryby adresowania
|
Tryb adresowania to sposób specyfikacji argumentu operacji. W zawężonym ujęciu oznacza sposób określenia (obliczenia) adresu danej w pamięci. Szerzej odnosi się również do rejestrów i stałych. |
Modele operacji warunkowych
|
Model operacji warunkowych jest to model określający sposób realizacji przez procesor operacji warunkowych. |
Warianty modelu operacji warunkowych:
- model ze znacznikami
- model bez znaczników
- model z predykatami
|
Znaczniki - jednobitowe rejestry atrybutów wyniku ostatnio wykonanej instrukcji (zwykle zgrupowane w jeden kilkubiowy rejestr). |
Znaczniki:
- Z - zero (przyjmuje stan 1 jeżeli wynik operacji wynosi 0)
- N/M (negative/minus) - znak (kopia najbardziej znaczącego bitu wyniku operacji)
- C/CY (carry) - przeniesienie/pożyczka
- O/V/OV (overflow) - nadmiar (nadmiar w kodzie U2)
- AC/HC (auxillary/ half carry) - przeniesienie pomocnicze BCD
- P (parity) - parzystość (przyjmuje stan 1 jeżeli liczba jedynek w najmniej znaczącym bajcie wyniku operacji jest parzysta)
 do góry
do góryCISC, RISC, VLIW
Istnieją trzy główne podejścia do kompozycji modelu programowego, określane skrótami RISC, CISC i – pochodzące od koncepcji RISC – podejście VLIW.
CISC
- Podejście stosowane w latach 60tych i 70tych XX wieku.
- Zakłada odpowiedniość między instrukcjami procesora i instrukcjami języka wysokiego poziomu (instrukcja wysokiego poziomu jest zamieniana na jedną lub kilka instrukcji procesora).
- Rejestru służą tylko do tymczasowego przechowywania wyników pośrednich i adresów, dane znajdują się w pamięci (instrukcje operują na danych w pamięci).
- Instrukcje operują naargumentach o różnych długościach: bajty, słowa 16-, 32- ew. 64-bitowe (długość argumentu jest zapisana w kodzie instrukcji).
- Bogaty repertuar trybów adresowania.
- Maksymalnie 16 rejestrów
- Operacje warunkowe - najczęściej z użyciem znaczników.
- Dominują instrukcje warunkowe - wynik zastępuje argument źródłowy.
Specyfikacja dwóch argumentów wymaga mniejszej liczby bitów w obrazie binarnym instrukcji niż specyfikacja trzech argumentów.
Rejestry perzechowują wyniki obliczeń - nowy wynik tymczasowy zastępuje poprzedni. - Skomplikowane instrukcje wymagają złożonej jednostki wykonawczej.
- Duża liczba odwołań do danych w pamięci spowalnia wykonanie programu.
- Duża liczba i złożoność trybów adresowania powoduje wydłużenie pól specyfikacji argumentów w zapisie binarnym instrukcji.
RISC
- Podejście RISC wprowadzono na początku lat 80tych XX wieku (projekt IBM 801, architektury MIPS i Berkeley RISC).
- Ważniejsze współczesne architektury RISC:
» MIPS
» SPARC
» ARM - Skalarne dane lokalne procedury są przechowywane w rejestrach. Odwołania do pamięci głównie w prologu i epilogu procedury - przeładowanie ramki stosu.
- Duży zestaw rejestrów - minimalnie 16, zwykle przynajmniej 32 (rejestry powinny mieścić skalarne argumenty i lokalne procedury).
- Instrukcje trójargumentowe - nie niszczą argumentów źródłowych (dane lokalne nie są zamazywane podczas wykonywania na nich operacji).
- Rzadkie odwołania do pamięci nie wymagają złożonych trybów adresowania (proste kodowanie instrukcji).
- Proste insrukcje dają się wykonać w prostej i szybkiej jednostce wykonawczej.
» Każda instrukcja ma tylko jeden argument docelowy
» Najwyżej jedno odwołanie do pamięci. - Złożone operacje można zsyntetyzować z kilku instrukcji.
- Instrukcje arytmetyczne i logiczne operują tylko na dancyh w rejestrach i argumentach natychmiastowych (długość argumentu jest zwykle równa długości rejestru, brak operacji 8-, i 16bitowych).
- Tylko dwa rodzaje instrukcji operują na pamięci:
» Load - ładuj
» Store - składuj
Tzw. "architektura load/store" - Więcej instrukcji - dłuższa postać binarna programu.
- Wszystkie instrukcje mają taką samą długość obrazu binarnego (zwykle 32 bity).
- Jeden lub dwa tryby adresowania pamięci - rejestrowy pośredni z przemieszczeniem, ew. dwurejestrowy pośredni.
VLIW
VLIW (ang. Very Large Instruction Word Architectures) jest architekturą wywodzącą się z podejścia RISCowego, jednak z bardzo dużym słowem instrukcji.
Architektury
von Neumanna
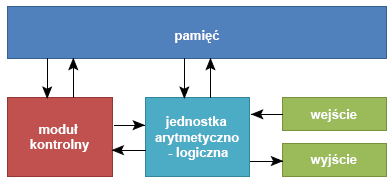
- Instrukcje tworzące program są przechowywane w pamięci w taki sam sposób, jak dane.
- Pamięć składa się z pewnej liczby ponumerowanych komórek:
» dostęp do pamięci następuje poprzez podanie przez procesor numeru komórki
» numer komórki nazywamy adresem - Z powyższych postulatów wynika w praktyce, że:
» zazwyczaj komputer będzie pobierał kolejne instrukcje programu z kolejnych komórek pamięci
» komórki te będą wybierane przez zwiększający się adres, który powinien być przechowywany i inkrementowany w procesorze
» adres ten jest przechowywany w specjalnym rejestrze - tzw. liczniku instrukcji (Program Counter- PC)
Harwardzka
|
Architektura harwardzka - realizacja maszyny von Neumanna z oddzielnymi hierarchiami pamięci programu i danych. |
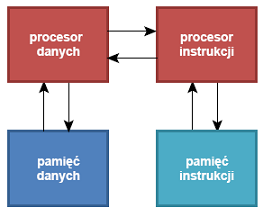
- Jest często uznawana za architekturę nie-vonneumannowską ze względu na dyskusyjność zachowania postulatu o jednakowym składowaniu instrukcji i danych.
- Posiada wysoką wydajność dzięki możliwości równoczesnego pobierania instrukcji i operacji na hierarchii pamięci danych.
- Brak możliwości zapisu instrukcji do hierarchii pamięci instrukcji:
» brak możliwości programowania
» komputer dostarczany ze stałym programem
» dopuszczalne tylko w zastosowaniach wbudowanych lub DSP
Princeton
|
Architektura Princeton - wzorcowa realizacja maszyny von Neumanna ze wspólną hierarchią pamięci instrukcji i danych |
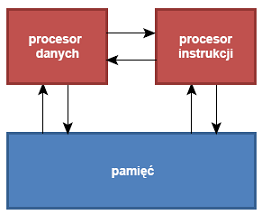
- Wspólna hierarchia wyklucza równoczesne pobieranie instrukcji i operacje na danych (tzw. von Neumann bottleneck).
- Nieograniczone możliwości modyfikacji programu:
» obiekt zapisany przez procesor danych do hierarchii pamięci jako dana może być następnie pobrany przez procesor instrukcji jako instrukcja
» możliwość programowania - potrzebna w komputerach uniwersalnych
» program może sam siebie modyfikować (automodyfikacja) - nie zawsze jest to pożądana cecha
Harward-Princeton
|
Architektura Harvard-Princeton - realizacja maszyny von Neumanna z oddzielnymi górnymi warstwami hierarchii pamięci i wspólnymi warstwami dolnymi. Przynajmniej jeden poziom kieszeni jest oddzielny dla procesorów instrukcji i danych. |
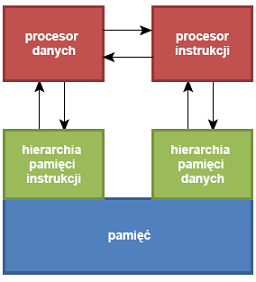
- Większość odwołań do hierarchii pamięci jest realizowanych w górnych warstwach (szybkie działanie dzięki równoległości dostępów jak w architekturze Harvard).
- Wspólne dolne warstwy hierarchii umoŜliwiają zapis programu (programowalność- niezbędna w komputerach uniwersalnych)
- Program użytkowy nie ma pełnej kontroli nad położeniem obiektów w hierarchii pamięci (brak możliwości automodyfikacji).
- Kontrolę taką może mieć system operacyjny:
» jeden program (proces) może modyfikować drugi
» możliwość ładowania programu np. z pliku - Architektura Harvard-Princeton zaspokaja potrzeby programowalności bez narażania bezpieczeństwa (automodyfikacja jest niebezpieczna).
 |
Większość współczesnych komputerów uniwersalnych jest opartych o architekturę Harvard-Princeton (w tym wszystkie współczesne komputery PC). |
Jak wykonać instrukcję
Procesor jednocyklowy
Procesory o prostym modelu programowym można zrealizować w postaci układu sekwencyjnego, który podczas każdej instrukcji zmienia stan tylko jeden raz - na końcu instrukcji.
- Całe wykonanie instrukcji odbywa się w układzie kombinacyjnym.
- Założenia dla modelu procesora:
» model programowy MIPS (RISC) z uproszczeniami
» architektura Harvard - rozdzielone pamięci programu i danych
» pamięć programu jest pamięcią stałą (ROM), czyli układem kombinacyjnym
» instrukcje o długości 32 bitów zapisane w pamięci o szerokości słowa równej 32 bity - Adresowanie pamięci - bajtowe (wymuszone wyrównanie naturalne danych i instrukcji).
Procesor wielocyklowy
- Architektura wielocyklowa minimalizuje liczbę bloków funkcjonalnych poprzez wielokrotne wykorzystanie bloków podczas każdej instrukcji.
- Implikuje to konieczność rozbicia wykonania instrukcji na kilka faz – cykli:
» w każdej fazie każdy blok wykonuje jedną czynność
» liczba faz wynosi od dwóch do kilkunastu, w zależności od budowy procesora i złożoności danej instrukcji
» poszczególne instrukcje mają różne czasy wykonania - Do sterowania wykonaniem służy skomplikowany układ sterujący, będący złożonym automatem synchronicznym.
- Komplikacja dróg przepływu danych implikuje wzrost liczby multiplekserów.
- Wspólna pamięć programu i danych
» architektura Princeton
» programowalność
» dwu- lub trzykrotne użycie pamięci podczas wykonania instrukcji - Wielokrotne wykorzystanie sumatora:
» do inkrementacji PC
» do wykonania operacji arytmetycznej
» do wyliczenia adresu docelowego skoku - Wielofazowe wykonanie powoduje konieczność zapamiętania pobranej instrukcji
» służy do tego tzw. rejestr instrukcji (IR-instruction register), umieszczony w jednostce sterującej
» w fazie pobrania rejestr ten jest ładowany obrazem instrukcji pobranym z pamięci
Procesor potokowy
Przetwarzanie potokowe jest jednym ze sposobów równoległego przetwarzania danych informatycznych.
Sposób działania: cykl przetwarzania dzieli się na odrębne bloki przetwarzania, z których każdy oprócz pierwszego i ostatniego jest połączony z następnym. Dane po przejściu przez jeden blok trafiają do następnego, aż osiągną ostatni blok. Dzięki temu, że przetwarzanie odbywa się w rozdzielnych blokach system może przetwarzać jednocześnie tyle danych ile zdefiniowano bloków. Zasadę działania potoku można porównać do produkcji taśmowej.
Tak działający procesor nazywamy potokowym.
|
Niemal wszystkie procesory budowane od połowy lat 80tych bazują na potokowych jednostkach wykonawczych. |
 |
Sprawdź sięSwoje wiadomości z tego działu możesz sprawdzić tutaj |
szukaj
legenda
|
definicja |
|
ważne! |
|
test |
 |
ciekawostka |