Dla celów ilustracyjnych wykorzystano zbiór danych iris pochodzący z bazowego pakietu datasets. Ponieważ zbiór ten zawiera identyczną ilość danych dla każdego z gatunków, postanowiono pozbyć się paru wpisów w celu urozmaicenia wykresów. Pierwszych 6 wierszy zbioru wygląda następująco:
|
1 2 3 4 5 6 7 8 9 |
> new_iris <- iris[-c(1:5, 101:125), ] > head(new_iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa |
Histogram
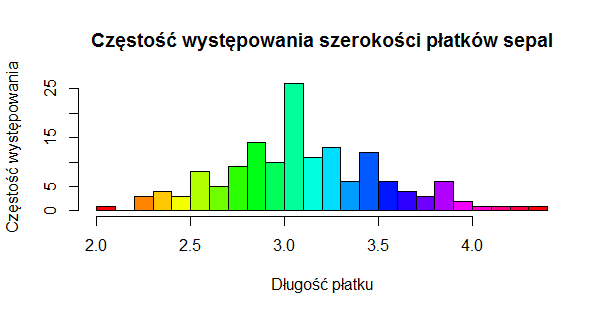
Histogram umożliwia nam zaprezentowanie rozkładu zmiennej liczbowej. Rezultatem jest możliwość odczytania częstości występowania poszczególnych wartości w serii danych. Przykładowo w stworzonym przez nas poniżej histogramie szerokość płatku sepal wynosząca 3.0 występuje w 25 instancjach zbioru danych iris.
|
1 2 3 4 5 6 7 8 9 10 |
# ilość unikalnych wartości dla długości kwiatu sepal liczba_unikalnych <- length(unique(iris$Sepal.Width)) # rysujemy histogram hist(iris$Sepal.Width, breaks = liczba_unikalnych, # ustawiamy liczbę słupków na liczbę unikalnych wartości right = FALSE, main = "Częstość występowania szerokości płatków sepal", xlab = "Długość płatku", ylab = "Częstość występowania", col = rainbow(liczba_unikalnych)) |
Wykres pudełkowy
Wykres pudełkowy wizualizuje 5 podstawowych statystyk dla rozkładu zmiennej liczbowej: wartość minimalną, pierwszy kwartyl (kwantyl rzędu 0.25), medianę, drugi kwartyl (kwantyl rzędu 0.75) oraz wartość maksymalną. W przykładzie zwizualizujemy zmienną charakteryzującą szerokość kwiatu sepal:
|
1 |
boxplot(iris$Sepal.Width, main = "Podstawowe staystyki dla szerokości kwiatu sepal") |
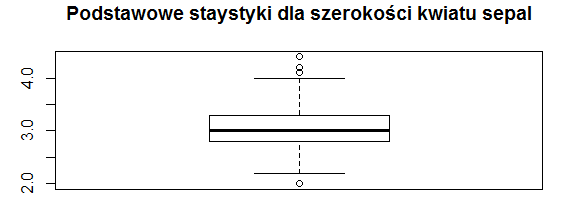
Idąc od dołu odczytujemy następujące wartości: wartość minimalna (2.3 – dolny wąs), pierwszy kwartyl (2.8 – dolna krawędź pudełka), mediana (3 – gruba linia na środku pudełka), trzeci kwartyl (3.3 – górna krawędź pudełka) oraz wartość maksymalna (4 – górny wąs). Kółeczka oznaczają marginalne wartości, odrzucane przy wyliczaniu podstawowych statystyk.
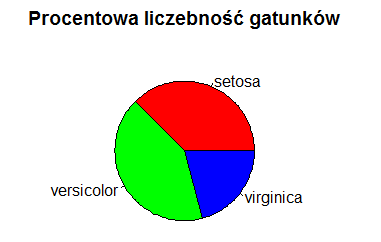
Wykres kołowy
Największą bolączką pokazanego wykresu kołowego jest próba rozróżnienia liczebności gatunków setosa i versicolor. Różnica procentowa pomiędzy nimi wynosi 4.1% i jest ciężka do zaobserwowania.
|
1 2 3 4 |
# procentowy udział każdego z gatunków w zbiorze danych percentage <- table(new_iris$Species) / length(new_iris$Species) # rysujemy wykres pie(percentage) |
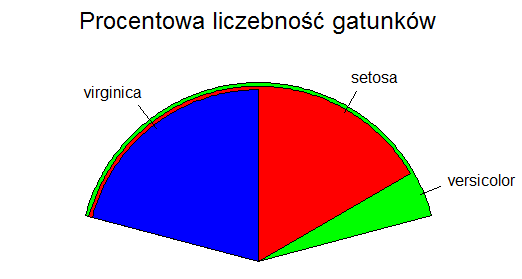
Wykres wachlarzowy
Problem rozróżnienia liczebności gatunków częściowo rozwiązuje wykres wachlarzowy, który lepiej ukazuje proporcje występujące pomiędzy wartościami. Wykres ten nie jest częścią standardowego R i wymaga instalacji pakietu plotrix.
|
1 2 3 4 5 6 7 8 |
# instalacja pakietu plotrix install.packages("plotrix") # ładowanie pakietu plotrix library(plotrix) # wyliczenia procentowego udziału gatunków w zbiorze percentage <- table(new_iris$Species) / length(new_iris$Species) # stworzenie wykresu wachlarzowego fan.plot(percentage, labels = names(percentage), main = "Procentowa liczebność gatunków") |
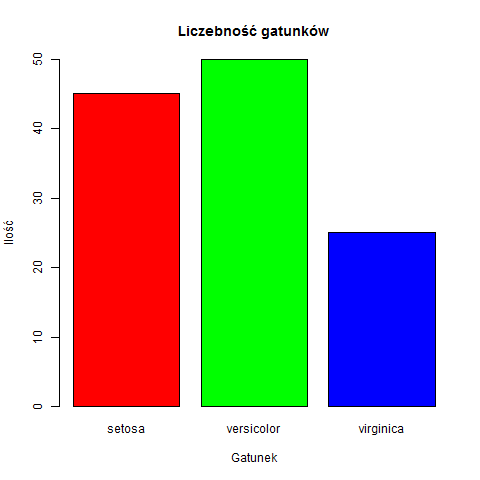
Wykres słupkowy
Wykres ten umożliwia wizualizacje wartości przy pomocy wysokości słupka. Posłuży nam do zaprezentowania dokładnej liczebności poszczególnych gatunków irysów. Do wyliczenia częstości występowania poszczególnych cech grupujących posłuży nam funkcja table().
|
1 2 3 4 5 6 7 8 9 10 11 |
# liczebność każdego z gatunków count <- table(new_iris$Species) # generujemy trzy kolory colors <- rainbow(3) # rysujemy wykres barplot(count, main = "Liczebność gatunków", ylim = c(0, 50), xlab = "Gatunek", ylab = "Ilość", col = colors) |